Mastering Postgres (by Aaron Francis)
postgres
Just jotting down some quick notes and learnings from the video course by Aaron Francis.

Advanced Data Types
Sequences
CREATE SEQUENCE IF NOT EXISTS users_id_seq
AS BIGINT
START WITH 1
INCREMENT BY 1
MINVALUE 1
SELECT NEXTVAL('users_id_seq'); will return the next value in the sequence.
SELECT CURRVAL('users_id_seq'); will return the current value in the sequence.
- Note: This is “current value” of this session and not global value (not affected by other sessions)
SELECT SETVAL('users_id_seq', 100); will set the current value of the sequence to 100.
- Note: Be careful with using this. For example, avoid setting the sequence to an auto-incremented number already used as a primary key.
Network and mac addresses
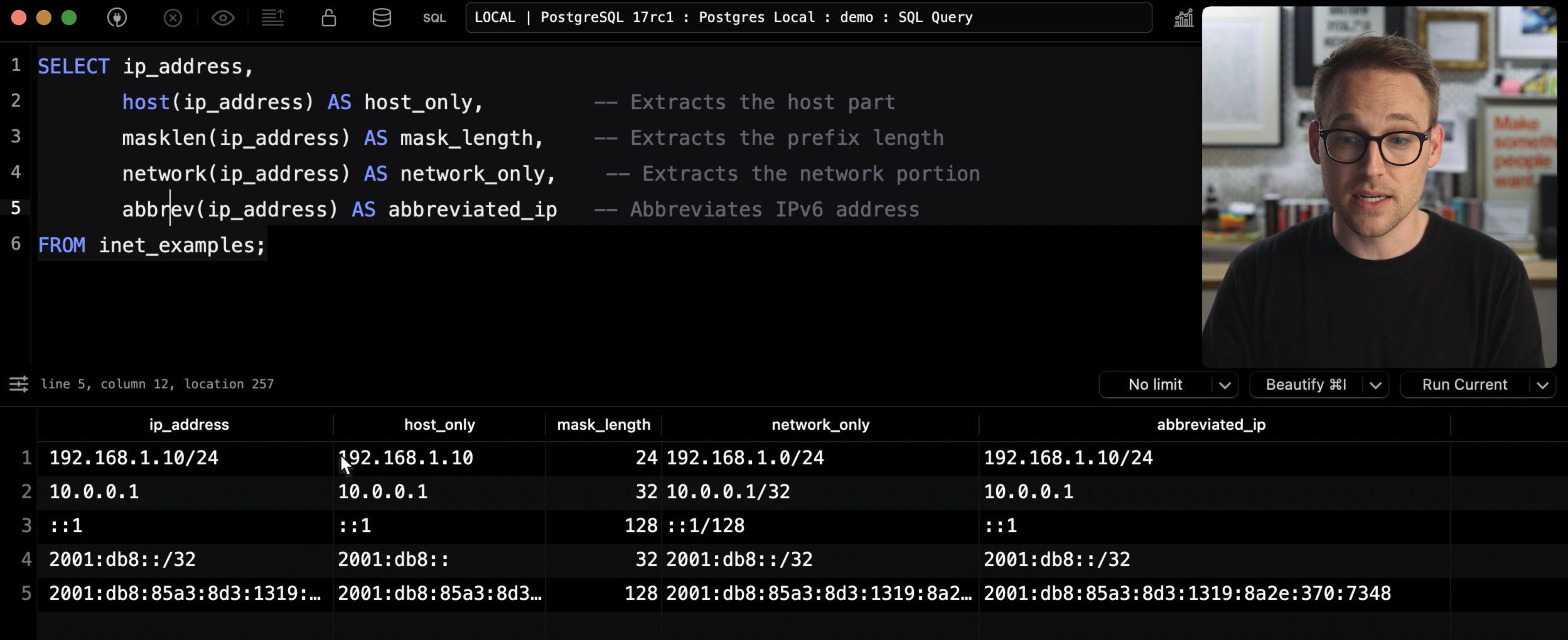
CREATE TABLE inet_examples (
ip_address INET
);
INSERT INTO inet_examples (ip_address) VALUES
('192.168.1.10/24'), -- host address using subnet mask
('10.0.0.1'), -- host address without subnet mask
('::1/128'), -- IPv6 loopback address
('2001:db8::/32'), -- IPv6 network
('2001:0db8:85a3:0000:0000:8a2e:0370:7334/128'), -- IPv6 host address
JSON / JSONB
TL;DR: always use JSONB
- JSON is stored as text under the hood, such as white spaces, new lines, etc.
- JSONB is larger in size but is more robust
- remove extra white spaces, new lines, etc.
- remove duplicate keys
- reorder keys if needed (since keys are unordered in JSON)
Querying JSON
SELECT data->'name' FROM ...
- Return value of
namekey in thedataJSON object - E.g.
{"name": "John Doe"}will return"John Doe" - Also can shorthand to
data#>'{customer,name}'(cleaner)
SELECT data->>'name' FROM ...
- Return value of
namekey in thedataJSON object as text - E.g.
{"name": "John Doe"}will returnJohn Doe - Also can shorthand to
data#>>'{customer,name}'(cleaner)
SELECT data->'items'->0 FROM ...
- Return the first item in the
itemsarray in thedataJSON object - E.g.
{"items": [{"name": "Item 1"}, {"name": "Item 2"}]}will return{"name": "Item 1"} - Can also use
->-1to return the last item in the array
SELECT jsonb_path_query(data, '$.items[0]') FROM ...
- Return the first item in the
itemsarray in thedataJSON object - Same as
data->'items'->0 - Cons: Need to add weird
#>> '{}'to return the value as text
... WHERE data ? 'items'
- Return all rows where the
dataJSON object contains theitemskey
... WHERE data ?| array['name', 'email']
- Return all rows where the
dataJSON object contains thenameoremailkey
... WHERE data ?& array['name', 'email']
- Return all rows where the
dataJSON object contains bothnameandemailkeys
Creating JSON objects
SELECT row_to_json(t)
FROM (
SELECT id, name, email
FROM users
) t;
-- Results:
-- {"id":1,"name":"John Doe","email":"[email protected]"}
-- {"id":2,"name":"Jane Doe","email":"[email protected]"}
Creating JSON arrays (typically more useful)
SELECT json_agg(row_to_json(t))
FROM (
SELECT id, name, email
FROM users
) t;
-- Results:
-- [
-- {"id":1,"name":"John Doe","email":"[email protected]"},
-- {"id":2,"name":"Jane Doe","email":"[email protected]"}
-- ]
Updating JSON
SET settings = settings - 'theme'
- Remove the
themekey from thesettingsJSON object
SET settings = settings || '{"theme": "dark"}'::jsonb
- Add the
themekey to thesettingsJSON object
SET settings = jsonb_set(settings, '{"config,theme"}', 'dark')
- Add the
themekey to thesettingsJSON object
Array
SELECT example_array[1] FROM ...
- Will return the first element of the array.
- PG uses 1-based index for arrays (first element is at index 1)
... WHERE example_array @> ARRAY['hello']
- Will return all rows where the
example_arraycontainshello
... WHERE example_array && ARRAY['hello']
- Will return all rows where the
example_arrayoverlaps with['hello']
SELECT UNNEST(example_array) FROM ...
- Will unnest the array into a set of rows.
Generated Columns
STOREDmeans the generated column’s value is saved on disk for quicker access, using more storage.- We cannot manually update a generated column (will throw an error)
Example 1 (height conversion)
CREATE TABLE users (
height_cm numeric,
height_in numeric GENERATED ALWAYS AS
(height_cm / 2.54) STORED
);
Example 2 (email domain extraction)
CREATE TABLE users (
email text,
email_domain text GENERATED ALWAYS AS
(split_part(email, '@', 2)) STORED
);
Example 3 (text to tsvector)
CREATE TABLE posts (
body text,
search_vector_en tsvector GENERATED ALWAYS AS
(to_tsvector('english', body)) STORED
);
Range
[and]is inclusive,(and)is exclusive
CREATE TABLE range_examples (
int_range int4range, -- integer range (discrete integer values)
num_range numrange, -- numeric range (includes decimal)
date_range daterange, -- date range
ts_range tsrange -- timestamp range
);
... WHERE int_range @> 5
- Will return all rows where the
int_rangecontains5
... WHERE int_range && '[3, 7]'
- Will return all rows where the
int_rangeoverlaps with[3, 7] - e.g. can use exclusion too
... WHERE int_range && (3, 7)
SELECT int4range[10, 20] * int4range(15, 25) FROM ...
- Will return the intersection of the two ranges (e.g.
[15, 21))
SELECT '{[3,7], [8,9]}'::int4multirange
- Will return a range containing 3,4,5,6,8,9 (7 is excluded)
Composite Types
-- Define the type
CREATE TYPE address AS (
street text,
city text,
state text,
postal_code text
);
-- Create a table with the type
CREATE TABLE addresses (
address address
);
-- Insert a row with the type
INSERT INTO addresses (address) VALUES
ROW('123 Main St', 'Anytown', 'CA', '12345')::address;
-- Accessing the fields (bracket notation)
-- Without brackets, DB will think it's a table name and throw an error
SELECT (address).street FROM addresses;
Indexes
When to use indexes
Cardinality
Number of unique values in a column
SELECT COUNT(DISTINCT column_name) FROM table_name;
Selectivity
Ratio (number of unique values / total number of values)
SELECT COUNT(DISTINCT column_name) / COUNT(*) FROM table_name;
- Higher selectivity = more efficient index (e.g., primary key)
- For example, for 1 million users and 10 unique countries, selectivity is 0.00001, indicating low index efficiency.
- However, if there’s 1 million users and 2 unique countries (99% Singapore, 1% Malaysia), while selectivity is low at 0.000002, adding index will improve performance if we are querying for the minority (users in Malaysia), but not for the majority (users in Singapore).
Partial Indexes
If we still want to add index, we can use WHERE to limit the rows to include in the index.
For this example, if we have multiple rows of users with same email but frequently search for active users, we can add index to only include rows where deleted_at is NULL.
CREATE INDEX my_index
ON users (deleted_at)
WHERE deleted_at IS NOT NULL;
Composite Indexes
- Orders matter for composite indexes
- Equality on the left, range scans on the right
- e.g.
CREATE INDEX example_index ON users (first_name, last_name, birthday);.
- Not always true, but a single composite indexes are more efficient than multiple single-column indexes
- Composite indexes is faster when using a
ANDin WHERE clause - However, multiple single-column indexes are faster when using a
ORin WHERE clause
- Composite indexes is faster when using a
Covering Indexes
Indexes that include all the columns needed for a query (SELECT, WHERE, ORDER BY, etc.)
For example, we need first_name, last_name, and id in this query
SELECT first_name, last_name, id
FROM users
WHERE first_name = 'John' AND last_name = 'Doe';
A covering index for this query would be
CREATE INDEX my_index ON
users (first_name, last_name, id);
However, we might want to exclude id in the index since it’s not used in the query. Instead, we can use INCLUDE.
CREATE INDEX my_index
ON users (first_name, last_name)
INCLUDE (id);
The upsides are:
- Smaller index size + Avoid b-tree bloat
- Improved INSERT/UPDATE performance
Ordering indexes
CREATE INDEX my_index
ON users (created_at, deleted_at)
This above index will be used when doing:
... ORDER BY created_at ASC, deleted_at ASC... ORDER BY created_at DESC, deleted_at DESC(backward index scan)
However, if we order in different direction e.g. created_at ASC, deleted_at DESC, the index will not be used. To do that, we need to add ordering in the index.
CREATE INDEX my_index
ON users (created_at ASC, deleted_at DESC)
This index will be used for both:
... ORDER BY created_at ASC, deleted_at DESC... ORDER BY created_at DESC, deleted_at ASC(backward index scan)
But by doing so, it then won’t be used when we order by both ASC/DESC.
NULLS
By default, (when doing ASC) NULLs are ordered last as they are the largest value.
We can override this by using NULLS FIRST (or NULLS LAST when doing DESC).
CREATE INDEX my_index
ON users (created_at ASC NULLS FIRST)
Functional Indexes
Indexes that use a function to create the index key.
CREATE INDEX my_index
ON users ((split_part(email, '@', 2)))
-- note: need to wrap it in parentheses because it's an expression
This index will be used for queries like ... WHERE split_part(email, '@', 2) = 'gmail.com'.
NOTE: This index will only be used when the query is exactly the same as the index. It won’t be used for queries like ... WHERE split_part(email, '@', 1)
Nevertheless, still useful in cases where a 3rd party system is querying the data in ways where we have no control over the query since we are still able to add the index.
Hash Indexes
By default, indexes are B-tree indexes.
Hash indexes are faster for equality checks (e.g. WHERE column = 'value') but not used for range scans (e.g. WHERE column > 'value').
Rule of thumb: ONLY use hash indexes when:
1) columns that are used in equality checks (or IN clause)
2) dealing with a very large number of rows
Understanding Query Plans
Scan Types
Reading rows from physical disk is expensive, so we want to minimize the number of disk reads. Here’s the order from slowest to fastest:
| Scan Type | Description |
|---|---|
| Sequential | Read the entire table in physical order |
| Bitmap index | Scans the index, produces a map, then reads pages in physical order |
| Index | Scans the index, then reads pages (without any order) |
| Index only | Scans the index (RE: Covering Index) |
Reading output
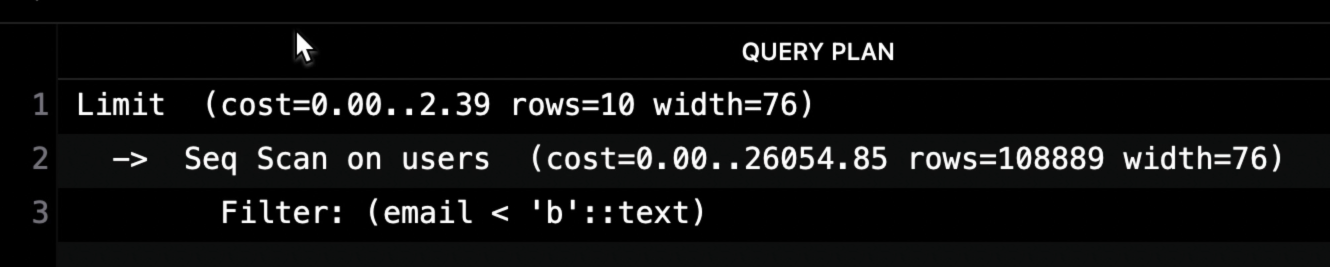
Example:
Bitmap Heap Scan on users (cost=33356.31..18398.43 rows=108889 width=76)
| Metric | Value | Description |
|---|---|---|
| startup cost | 33356.31 | Before starting the scan Need to wait for all children nodes to complete |
| total cost | 18398.43 | Inclusive of cost of children nodes |
| rows | 108889 | Estimated number of rows it will return to parent node |
| width | 76 | Estimated number of bytes returned per row |
Note: total cost will be thrown off if we use a LIMIT in the query (and no ORDER BY). For example, the parent node (LIMIT) has a lower total cost than the children nodes (Seq Scan)
Advanced SQL
GROUP
BOOL_AND, BOOL_OR
-- returns true if any sale is greater than 1000
-- bool_and returns true if all sales are greater than 1000
SELECT
employee_id,
bool_or(amount > 1000)
FROM sales
GROUP BY employee_id;
FILTER
-- count the number of sales greater than 1000
SELECT
employee_id,
count(*) FILTER (WHERE amount > 1000)
FROM sales
GROUP BY employee_id;
Window Functions
OVER, PARTITION
SELECT
employee_id,
-- get the first sale amount for each employee
first_value(amount)
OVER (PARTITION BY employee_id ORDER BY date),
-- get the last sale amount for each employee
-- note: first_value + desc
first_value(amount)
OVER (PARTITION BY employee_id ORDER BY date DESC)
FROM sales;
Frames (ROWS)
SELECT
employee_id,
sum(amount) OVER (
PARTITION BY employee_id
ORDER BY date
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
-- or ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
-- or ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
)
FROM sales;
Examples
This query fetches all bookmark details for each user, while also numbering the bookmarks and identifying the first and last bookmarks for each user.
SELECT
*,
row_number() OVER user_bookmarks,
first_value(id) OVER user_bookmarks,
last_value(id) OVER user_bookmarks
FROM bookmarks
WINDOW
user_bookmarks AS (
PARTITION BY user_id
ORDER BY id ASC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
)
Recursive CTE
Note: Ensure there’s end condition in the recursion.
Example 1 (ascending numbers generator)
WITH RECURSIVE numbers AS (
-- anchor
SELECT 1 AS n
UNION ALL
-- recursion
SELECT n + 1 FROM numbers WHERE n < 10
)
SELECT * FROM numbers;
Example 2 (random numbers generator)
WITH RECURSIVE random_numbers AS (
-- anchor
SELECT
1 as n,
(floor(random() * 10) + 1)::integer AS my_rand
UNION ALL
-- recursion
SELECT
n + 1,
(my_rand + floor(random() * 10) + 1)::integer
FROM random_numbers
)
SELECT * FROM random_numbers;
Putting column names in CTE
with recursive numbers (n, my_rand) as (
-- some query
)
Removing duplicates
WITH duplicates_identified AS (
SELECT
id, -- Assuming primary key
ROW_NUMBER() OVER (
-- unique identifier for each row
PARTITION BY user_id, url
ORDER BY id
) > 1 as is_duplicate
FROM bookmarks
)
DELETE FROM bookmarks WHERE id IN (
SELECT id FROM duplicates_identified WHERE is_duplicate = true
);
Upsert
EXCLUDEDis a special variable that contains the values of the row that would have been inserted if there were no conflicts.WHEREstatement is optional, but it’s useful to avoid updating the row if the condition is not met.
Example 1: Update only if the url is null
INSERT INTO bookmarks (user_id, url)
VALUES (1, 'https://example.com')
ON CONFLICT (user_id) DO UPDATE
SET url = EXCLUDED.url
WHERE bookmarks.url IS NULL;
Example 2: Add to the count on conflict
Create a user if it doesn’t exist, otherwise add to the bank balance.
INSERT INTO bookmarks (user_id, bank_balance)
VALUES (1, 100)
ON CONFLICT (user_id) DO UPDATE
SET bank_balance = bookmarks.bank_balance + EXCLUDED.bank_balance;
RETURNING
Reduces the need for another query to get the inserted data.
INSERT INTO
orders (customer_name, order_date, total_amount)
VALUES
('John Doe', '2024-01-01', 100.00)
RETURNING *; -- or RETURNING id (or other columns);
Full Text Search
Query
WHERE to_tsvector(title) @@ to_tsquery('star & wars');
- Must have both
starandwarsin the title
WHERE to_tsvector(title) @@ to_tsquery('star | wars');
- Must have either
starorwarsin the title
WHERE to_tsvector(title) @@ to_tsquery('star & !wars');
- Must have
starbut notwarsin the title
WHERE to_tsvector(title) @@ to_tsquery('star <-> wars');
- Must have
starfollowed bywarsin the title <->is equilvalent to<1><2>means it’s “star X wars” where X is any word (skip 1 word)
WHERE to_tsvector(title) @@ to_tsquery('star <-> (wars | trek)');
- Must have
starfollowed by eitherwarsortrekin the title
Ranking
SELECT
*,
ts_rank(
to_tsvector(title), -- base vector
to_tsquery('star & (wars | trek)'), -- query vector
1 -- weight (optional)
) AS rank
FROM bookmarks
ORDER BY rank DESC;
1as weight means it favours shorter results
Example 1: Assign heavier weight to title
... setweight(to_tsvector(title), 'A') || setweight(to_tsvector(title))
Example 2: Assign heavier weight on conditions
Assign higher weight to results with action genre.
ts_rank(
(
setweight(to_tsvector(title), 'A') ||
setweight(to_tsvector(title), 'B')
),
to_tsquery('fight')
) + (
-- note: vector max score is 1
case when genre = 'action' then 0.1 else 0 end
)
Websearch
These are useful helper methods for converting search queries to tsquery.
plainto_tsquery('star wars')
- Converts “star wars” to
star & wars
phraseto_tsquery('star wars')
- Converts “star wars” to
star <-> wars
websearch_to_tsquery('"star wars"')
- More Google-like and user friendly
- Will not throw error if the query is invalid
- Note: it is
websearch_toand notwebsearchto - Example:
"star wars"to'start' <-> 'wars' - Example:
"star wars" -cloneto'start' <-> 'wars' & !clone - Example:
"star wars" +cloneto'start' <-> 'wars' & clone - Example:
star wars or trekto'star' & 'wars' | 'trek'
pgvector
Note: assuming pgvector extension is installed.
CREATE TABLE products_v (
id BIGINT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
name TEXT,
embedding VECTOR(4) -- 4 dimensions
)
Operators
Note: Refer to the recommendations of the data or model on what’s the best operator to use.
<+>is the L1 operator (l1)<->is the L2 operator (l2)<=>is the cosine similarity operator (cosine)<#>is the inner product operator (ip)
Example 1: 10-nearest neighbors
Find the 10 products with the highest cosine similarity to the vector (1, 2, 3, 4).
Note: (1,2,3,4) is the vector we are querying against. This is an embeddings returned from a model.
SELECT * FROM products_v
ORDER BY embedding <=> vector(1, 2, 3, 4)
LIMIT 10;
Example 2: 10-nearest neighbors (related products)
Assuming we have a product with id 1, we want to find the 10 most similar products.
SELECT * FROM products_v
WHERE id != 1
ORDER BY embedding <=> (
SELECT embedding FROM products_v WHERE id = 1
)
LIMIT 10;
Indexes
... USING ivfflat (embedding vector_cosine_ops) with (lists = 100)
vector_cosine_ops is the operator class for cosine similarity. You can also use vector_l2_ops for L2 distance.
Rule of thumb for lists: square root of the number of rows. Higher -> Improves recall/accuracy but increases query time and memory usage.
... USING hnsw (embedding vector_cosine_ops)
IVF Flat is a solid general-purpose index if resources allow. HNSW offers better performance and accuracy but is more costly.