Reducing Latencies and Downtime: Concurrent Refresh of Materialized View
optimization
database
postgresql
Context
Handling the vast amount of data required to compute salary information for NodeFlair Salaries was a challenge. To tackle this, we leveraged Materialized Views to speed up the process.
If you’re curious about the details, check out my previous blogpost on how this works.
🐌 Issue - It’s Slow and Down
Over time, we’ve noticed the latencies for NodeFlair Salaries creeping up, leading to some serious downtime.
Our average uptime, defined as loading times exceeding 5 seconds, plummeted to just 84% — yikes!
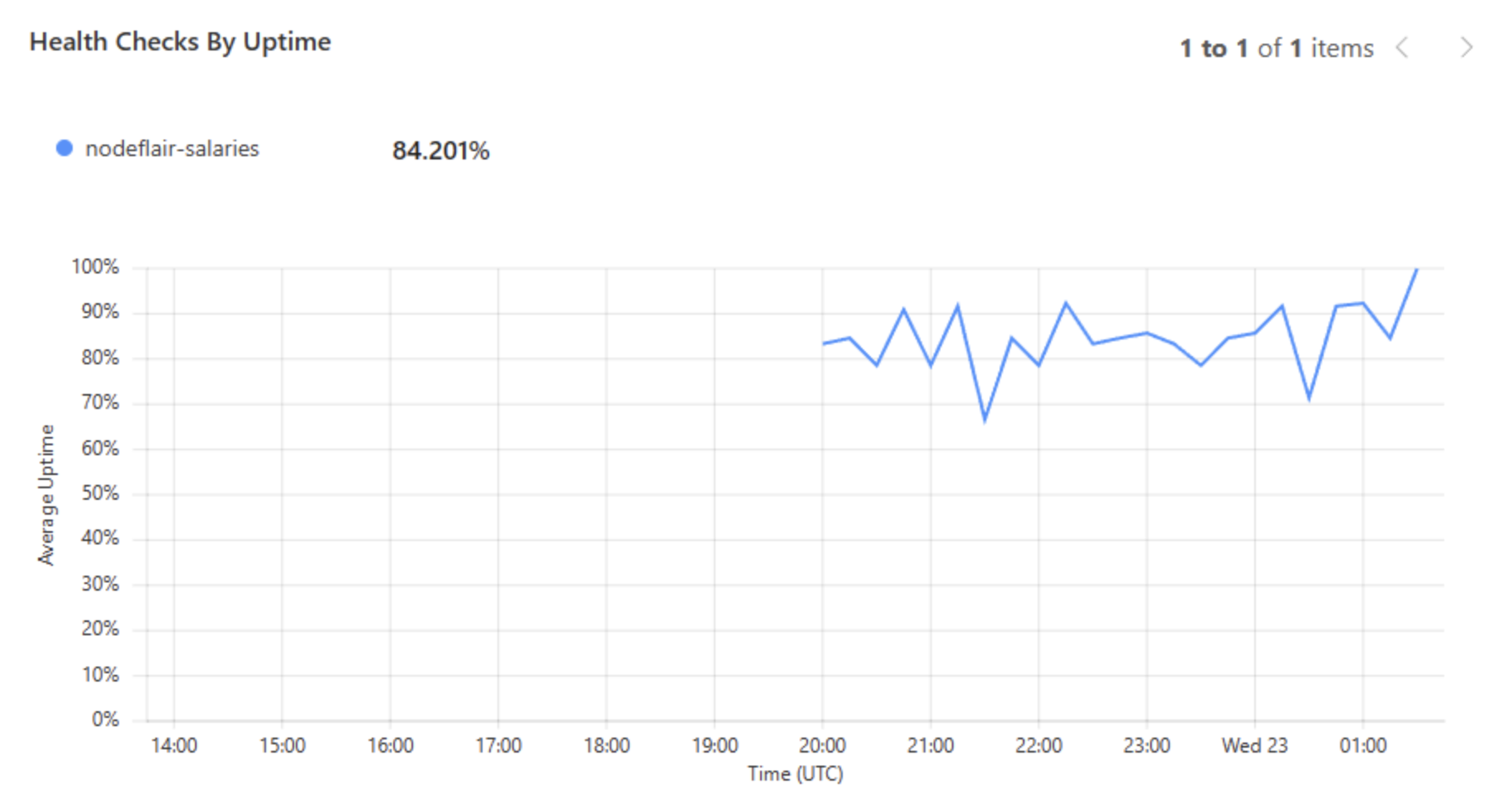
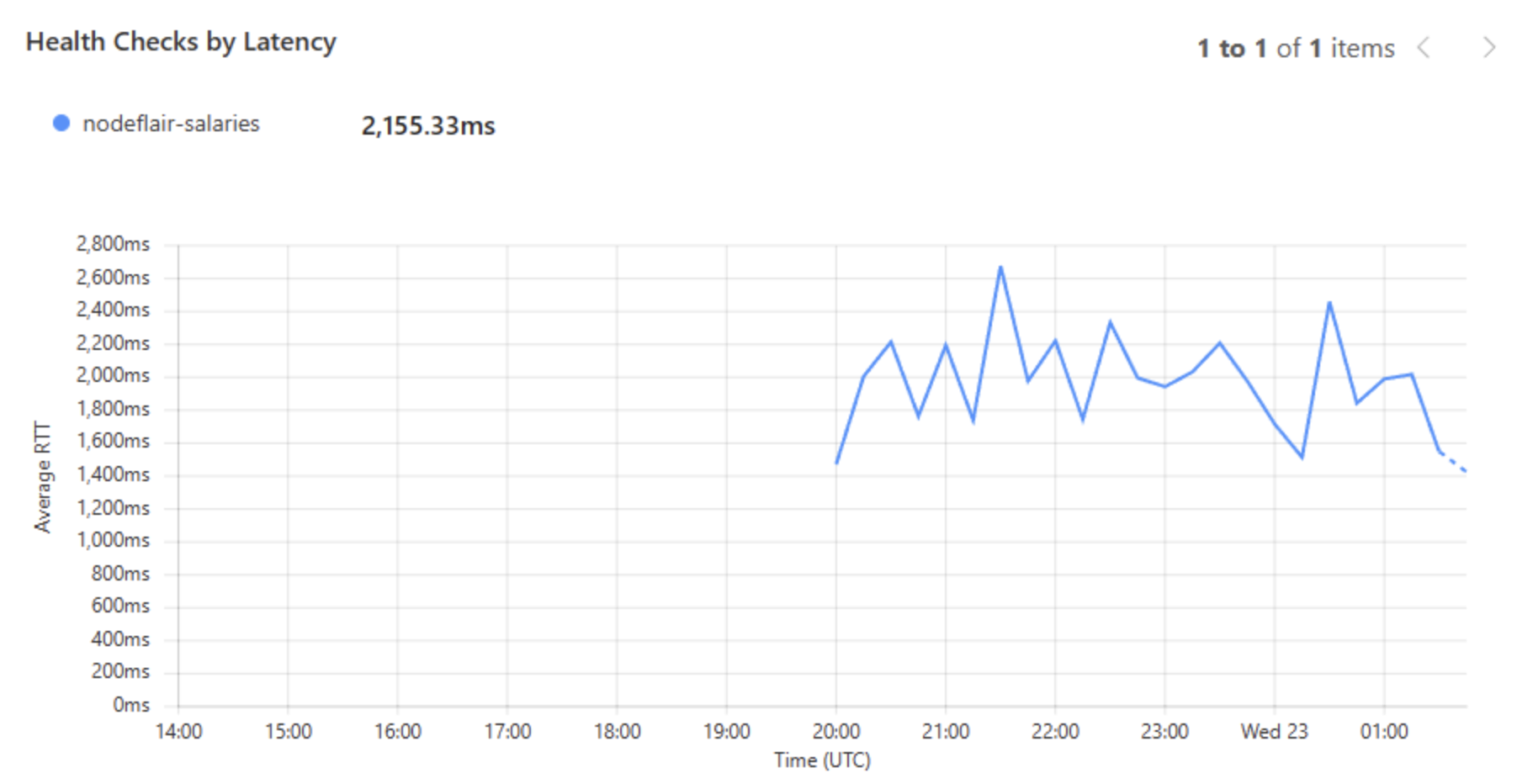
And the average latency? A staggering 2155ms. Just think about the pain for p0.9 and beyond!
🔎 The Investigations
I’ve been digging into Amazon RDS Performance Insights and it’s clear: our Average Active Sessions (AAS) are regularly blowing past the max vCPU limit of 2. We’re running on a t4g.medium instance, so this should be expected.
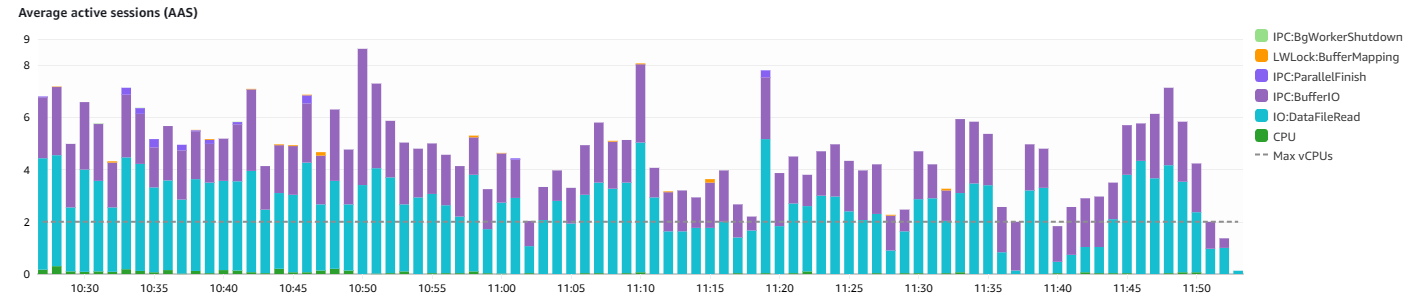
What’s driving this? It’s mostly IO:DataFileRead and IPC:BufferIO.
Reading into Amazon RDS’s documentation, here’s the TL;DR of the potential causes:
IO:DataFileRead- Your shared buffer pool might be too small. It’s time to upsize thatIPC:BufferIO- Typically happens when multiple connections are gunning for the same page while an I/O operation is still pending.
✅ The Solution - Concurrent Refreshing of Materialized Views
The IPC:BufferIO gave us a solid lead. It’s rare to see multiple connections hitting the same page during I/O—after all, we don’t change data THAT often.
Or maybe we do?
We’re using the Scenic gem for our database views. By default, it uses a non-concurrent refresh, which locks the view while it’s being updated.
We’ve made the switch to concurrent refresh to allow for real-time assessment during updates. Just remember, this needs unique indexes on the views - no biggie.
⚡ Now It’s Fast and Up!
The Upgrade - nodeflair.com/salaries: We slashed average latency by a staggering 64%, bringing it down from 2155ms to just 780ms. Downtime is now a thing of the past, dropping from 15.8% to a perfect 0%.
And that’s not all. Here are some additional wins:
- nodeflair.com: Average latency cut by 25%, from 1000ms to 750ms.
- nodeflair.com/jobs: Average latency improved by 20%, from 500ms to 400ms.
🙅♂️ Solutions I Considered But Didn’t Work Or Pursue
Here are some potential solutions I thought about but decided against due to cost or complexity. They remain options only if all else fails.
Caching
We hit a snag with Rails’ built-in Fragment Caching. The real bottleneck wasn’t in the views; it was in the database.
What about Low-Level Caching?
Rails defaults to MemoryStore for caching, but that’s not cutting it for us. With multiple EC2 servers, each with its own memory cache, other servers can’t access the data. Plus, Elastic Beanstalk’s auto-scaling and deployment cycles nuke cached data indirectly by creating new instances.
So, we switched gears and integrated Redis as our cache store — since we’re already using Redis with Sidekiq. This allowed us to cache results and invalidate them only when the view gets successfully materialized. We also cached other common, infrequently changing DB queries, which cut down on database load and improved response times.
Unfortunately, while it’s an improvement, it didn’t completely solve the issue.
Upgrading RDS Instance Type
t4g.large- Costs 2x more but only doubles the RAMt4g.xlarge- Provides 8GB of RAM and 4 vCPUs, but costs 4x more.
Partitioning
Partitioning is a new territory for me, and there’s a lot of uncertainty around its effectiveness.
Also, given our current data volume, it’s unlikely we need it at this stage.